An approach to shorten time-to-value for machine learning use-cases
Abstract
In this digital age of hyper competition and collaboration, AI/machine-learning enabled use cases hold the key to continuous & disruptive innovation in the post-CoronaVirus new norm business environment. After developing the initial experimental use-case, the enterprise needs an agile platform to deploy the model in their production environment in an accelerated manner. Sometimes data scientists and analysts take a lot of time in gathering data and utilizing it in their advanced analytics activities. There is a ‘need for speed’ and ‘efficiency’ of ML operational deployment. Currently there are good options such as GCP & Databricks cloud environments to deploy machine learning enabled use cases in a matter of hours. This document outlines one of the automated approaches for enterprises to deploy machine learning enabled use cases using rapid deployment GCP and Databricks platforms.
Problem Statement
Many enterprises leverage data sciences and machine-learning use-cases to extract insights from data today. These use cases classify existing data into logical categories or predict approximate ‘high-confidence’ probabilities of business outcomes. Business teams are always pressurizing the Data Analytics and IT teams to produce useful results faster via practical use-cases. Typical examples of these industry use-cases include:
- What product should be recommended to customer based on his demographics? What factor will increase the propensity to buy?
- How many units of a particular SKU product should be shipped to a given location, for optimal inventory management?
- What is the likelihood of component failure given associated operating parameters?
The machine learning use cases typically evolve based on the business circumstances, experimentation and continually growing requirements from business users in the CMO, CRO, CFO, CIO and COO organizations. While the backlog of requirements is growing fast, a lot of time is spent in data preparation (about 80%), modeling and prototyping initially. Simplification and automation to increase velocity of commercial delivery is difficult with many moving parts and non-standard approaches. In this article we will explore a holistic approach on how Databricks and GCP like platforms enable simplified and agile deployment of end-to-end production-ready use-cases.
Implementation
The exact steps to implement a use-case and algorithm could differ based on your organization’s requirement, however the steps given in this article will , overall, have a good resemblance to the steps that need to be implemented. There are multiple ways organizations can implement machine learning use cases. At a high level, a common approach can be summarized as follows:
1. Use any standard tools such as R Studio, PyCharm or plain notepad++ for playing with light dataset. There are several algorithms that can be implemented quickly to test out the datasets under consideration.
2. Iteratively develop machine learning algorithm after collaborative discussion with business and IT. This step could take several iterations; however, this is typical approach to develop a machine learning use case along with finalizing the parameters.
3. Once algorithm and approach are finalized, then the real deployment approach would be discussed. GCP and Databricks provides integrated platforms with tooling to quickly ingest the dataset and apply machine learning algorithms to it via notebooks.
Steps normally considered:
A. Ingest the datasets
Data ingestion in Databricks & GCP is greatly simplified using products like Infoworks’ DataFoundry, Fivetran, SyncSort or Streamsets. The data sources can be many, from business support and operational databases such as Oracle, MySQL, etc., to flat/CSV files, to SaaS applications like Salesforce, NetSuite, ServiceNow, Marketo, etc. Ingesting all this data into a unified data lake is often time-consuming and hard when using typical ETL tools, in many cases requiring custom development and dozens of connectors or Slowly changing dimensions (SCD-I/II) or APIs that change over time and then break the data onboarding process. Traditional companies use disparate data integration tools that require scores of data engineers to write manual scripts and schedule jobs, schedule triggers and handle job failures manually. This approach does not lend to simplification and scaling-up and creates painstaking operational overhead. So, use of automated data ops and orchestration tools are highly recommended to build a strong unified approach to data lake-housing.
Source: https://tinyurl.com/y6vgd6c9 (Databricks.com blog)

Typically, data processing and gathering can be divided into three sections:
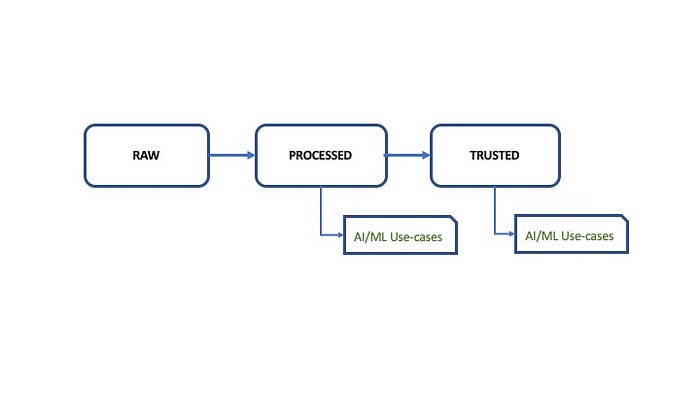
- Raw Data
- Processed Data
- Trusted Data
Raw data section is where the data, from diverse sources, lands. These sources could traditional databases such as MySQL, Oracle, or streaming data sources such as Kafka, or cloud-based data store such as S3, GCS or SaaS applications such as Salesforce, Jira, Freshdesk, ServiceNow, NetSuite, etc.
The processed section is where the data sources are processed and prepared for downstream applications such as business intelligence application. This section can feed into machine learning and artificial intelligence algorithms as well.
The final section of this is trusted datasets. These are the datasets which will contain data which can be directly consumed by business customers, data scientists and to some extent by IT data analysts.
There are several considerations for ingestions such as
- Incremental and full ingestions
- State management while loading the data, in the event of failure
- Data compaction
- Data de-duplication
- Dependency management
- Reconciliation of processed datasets.
Data scientists and ML modelers can work on data produced out of processed and trusted data sets as follows :
The main challenges for data ingestion and synchronizations are around
- fast initial data load and
- incremental data load once the initial data load is completed.
Simple questions such as how many partitions are required, how many mappers required could become challenges if the structure of the underlying dataset is not known. Typically, it is recommended that data ingestion, transformation and orchestration should have following features in some form:
-Data and metadata crawling
- Schema & Data Type discovery
- Data Pattern discovery
-Data Ingestion
- Parallel and secured ingestion
- Data validation and reconciliation
- Data type conversion
-Data and schema sync
- Continuous change data capture
- Continuous schema change capture
- Continuous merge process
- Auto time axis building
- Slowly changing dimensions (Type I & II)
B. Feature Engineering Model building and export
Once the ingested data is available in unified data lake, many tools such as Jupyter notebook, R Studio or PyCharm can be leveraged to create and export model. The choice of the tool depends on the use case. There are several toolkits available as well, such as TensorFlow, Scikit-Learn, etc. Some toolkits have better capabilities than others for given task.
The algorithm generated for the model can be exported in any format such as pmml, onnx, pickle and joblib. Sample code to extract the model in pmml format is as follows:
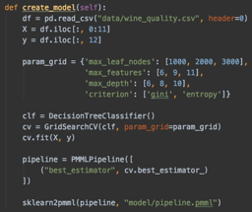
Similar function calls are available in TensorFlow as well. The model can be exported, as supported by the underlying toolkit.
Another alternative for generation of the model is to export model parameters. For example, decision tree can be exported using the code below:

source: StackOverFlow: https://stackoverflow.com/questions/20224526/how-to-extract-the-decision-rules-from-scikit-learn-decision-tree
Note — This is sample code, please use it appropriately to suit your needs.
This code will produce output as follows:
def tree(f0):if f0 <= 6.0:if f0 <= 1.5:return [[ 0.]]else: # if f0 > 1.5if f0 <= 4.5: …
Note — This is a sample output, please use appropriately to suit your needs.
Data scientist spend majority of their time in cleaning and organizing their data. Data processing platforms which has features such as ingestion and transformation can help with advanced feature engineering possibilities using pipelines and workflows to transform the data. Collecting large data set in tandem with other essential processing can be done using Infoworks/FiveTran/Streamsets like ingestion process.
The calls can be made to any data science toolkits, if required from pipelines as well. The function calls are compatible with other toolkits such as TensorFlow from Google and MLFlow from Databricks. The developed model can be exported, as supported by the underlying toolkit or can be exported to other environments with different infrastructure vendors as well.
C. Model Predictions
Once the model is created and tested using any toolkit, it should be deployed in production in an efficient manner. There are several ways to deploy the model in production, such as writing customer script using any of the languages of choice such as python, Scala, java etc. It can be deployed using any of the frameworks as well such as H2O. There are several platforms which can help with deploying the models. Key point post-deployment is to address model drift. It is essential to monitor and continuously address model drift to ensure the output and model accuracy is maintained in accordance with original business goals. In general, the platforms with built-in fictionally for data science are superior to platforms which need additional setup or configuration for data science integration, hence it would be advisable to ensure the platform has some kind of data science integration available, before standardizing the platform across various organizations.
Flexibility of model configuration is important to ensure data engineers and scientists get enough ‘play’ area to work on various parameters including feature engineering of the model.
Of course, there is plenty of features and parameters that a machine learning toolkit can leverage as this field is continuously evolving. It is hard for any platform to comprehensively include all the functionality of machine learning toolkit.
Other consideration is the reusability of the developed code throughout the various parts of the platform. For example if you have engineered few features for a decision tree for your customer segmentation for marketing, then similar code should allow customer segmentation for collection department as well.
Note: Some platforms like Infoworks’ DataFoundry allows you to insert ML logic in-line with their custom data transformation flows. This allows you to deploy the model in a more scalable and commercial format once finalized.
Conclusion
As can be seen from this article, there are several considerations to be made by data scientists and data engineers to create machine learning, artificial intelligence pipelines in an agile manner leveraging many features available on advanced platforms. Teams can either leverage their platforms’ built-in functionality or extend it using connectors, transformations to speed up the process. Since we worked closely with Infoworks products, we recommend leveraging Infoworks ‘Data Onboarding’ capabilities to ingest the data, so that it can be available to data scientist to build the model out more efficiently and in a Fail-fast-fail-cheaply (FFFC) manner. The details of onboarding (ingestion process and parameters) are available on the Infoworks Documentation website. Similar details can be procured from the Databricks community, GCP community and related automation tool sites. The savings are in terms of reducing manual ingestion, both initial and incremental combined with ease of deployment of advanced machine learning algorithms. The time savings it self should be substantial and help create a strong business case in terms of Total Cost of Ownership (or TCO for commercial operations of AI/ML). Keeping your enterprise’s business priorities and timeline in mind, the holistic platform should stand out in terms of flexibility, ease of use and time-to-value for many data science use cases. Do let us know your comments and feedback below on your best practices and suggestions. Thanks 🙏.
Authors : VirooPax B. Mirji and Ganesh Walavalkar
VirooPax Mirji (@ vpax) and Ganesh Walavalkar
p.s. These are personal views and should not be considered as representing any specific company or ecosystem of partners.
Credits to owners of some images and code snippets : #StackOverFlow , #Infoworks.io , #UnSplash and #Databricks
